par Christine Siméone publié le 15 août 2021 à 8h39
Internet Archive fête ses 25 ans cette année, mais savez-vous ce que l’on trouve sur cette plateforme anglosaxonne, dont l’objectif affiché est d’offrir un accès universel à la connaissance ? On a surfé sur ce site aux multiples tiroirs et on vous dit tout (ou presque).

Brewster Kahle, l’un des fondateurs de l’Internet Archive © Rory Mitchell, The Mercantile, 2020 – CC by 4.0
En France on connait bien Gallica, la base de documents numérisés de la Bibliothèque nationale de France, où l’on peut consulter des millions de documents, livres, photos, manuscrits. Aujourd’hui, la plupart des bibliothèques publiques francophones ou anglosaxonnes ont bâti de solides plateformes de ce type. Il y a en une un peu particulière au milieu de tout cela, c’est l’Internet Archive (archive.org). Elle est à la fois une bibliothèque de documents, un outil de numérisation utilisé par certaines institutions, et un lieu d’archivage des sites internet. Comme sur la calotte glaciaire, on peut y carotter des pages web, histoire de voir à quoi elles ressemblaient à différentes époques.
Une mine de documents
Trouver en ligne les anciens cours de l’Ecole Normale Supérieure, ceux de Louis Althusser et Etienne Balibar en 1968, par exemple. Feuilleter les 350 pages d’explication méthodique par ces philosophes les plus brillants de leur époque à l’intention des scientifiques. Ou bien retrouver le cours d’histoire romaine de Jules Michelet, manuscrit, toujours pour les élèves de l’ENS en 1830. Cela est possible en surfant dans les pages d’archive.org.
Ces manuscrits, ont été numérisés et rendus accessibles à ceux qui s’inscrivent sur cette plateforme anglo-saxonne, fondée en 96 avec pour objectif de permettre à tous d’accéder à toutes les connaissances. C’est un peu la « foire fouille » des contenus numériques. Des poèmes d’Emily Dickinson lus par des comédiens amateurs, à la finale de la ligue des champions en 93 entre Marseille et Milan, en passant par le textes de la Génèse, et une collection de films de Georges Méliès. Internet Archive ce sont donc des millions de vidéos, y compris des journaux TV, des films d’archives, et autres pépites audiovisuelles, plusieurs millions d’enregistrements audio, deux millions de livres, des centaines de milliers de logiciels, et des millions d’images.

À écouter - Culture Pourquoi Internet aime autant les archives ?
Une vieille utopie
On connait cette vieille marotte des utopistes de la connaissance ouverte à tous et toutes, notamment celles des fondateurs de l’internet et leurs suivants. C’est dans cette ligne que se situent les deux créateurs d’Internet Archive, Brewster Kahle et Bruce Gilliat. C’est ce qui explique leur « activisme numérisateur » aujourd’hui. Internet archive (IA) numérise tout ce qui se présente sous ses scanners, propose des fonctions d’analyse profonde des textes ou des recherches par métadonnées. Ainsi de nombreuses institutions, non sans quelques polémiques, lui confient les chantiers de numérisations des leurs collections. Là où les États anglo-saxons défaillent dans leurs stratégies patrimoniales, IA propose ses services et met à disposition de tous les documents.
Archive.org s’est aussi attelé à la sauvegarde des pages d’un certain nombre de médias. On trouve ainsi quelques deux millions d’archives télévisuelles captées un peu partout dans le monde. Si ça vous dit, vous pourriez regarder les Live de Fox News du 31 juillet dernier par exemple, ou bien remonter à des émissions de 2001.

À lire - Culture Gallica, la plus grande bibliothèque numérique, a 20 ans
Internet vu comme un objet culturel à sauvegarder
Mais archive.org réserve encore d’autres ressources. Kahle et Gilliat ont d’abord créé Alexa, un logiciel de recherche dans les bases de données abyssales des universités et des médias américains, avant de le revendre à Amazon en 1999. Dans le deal, il y avait une condition : toutes les recherches – et donc réponses trouvées – par le moteur Alexa devaient permettre d’enrichir l’Internet Archive, dans l’une de ses fonctions, à savoir, l’archivage du net.
Ainsi, Archive est aussi une formidable mémoire des sites internet, vus comme des objets patrimoniaux. L’idée est de traiter l’internet comme un patrimoine culturel nécessitant sauvegarde. En France c’est la Bibliothèque Nationale de France qui archive l’internet, et les pages disparues, oubliées, obsolètes. Dans le monde anglo-saxon et au-delà c’est l’Internet Archive. Kahle et son compère Gilliat ont ajouté en 2001 une corde à leur arc. La Wayback Machine, fonction de récupération des pages web écrasées ou modifiées, à l’usage des utilisateurs lambda. Cherchez une page web, la Wayback Machine, vous la présentera sous ses différents états au fil du temps.
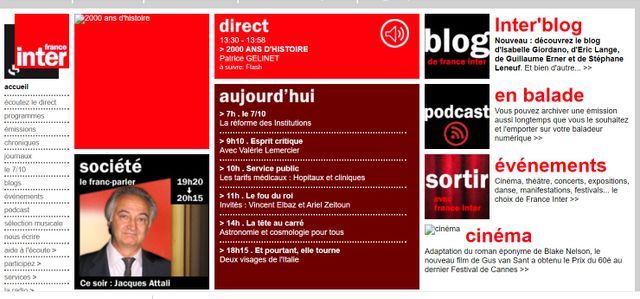
La homepage du site de France Inter le 8 janvier 2008 / Capture par Internet Archive
Archive.org a par exemple fait 18 000 captures du site de France Inter entre 2004 et 2021, et 406 000 captures du site l’histoire par l’image bien connu des professeurs français, ou 370 000 captures du site de la BnF. Ainsi retrouve-t-on la page d’accueil du site le 4 février 2005, au hasard, qui annonce les expositions du moment, et la grève des agents sur le site ce jour-là.
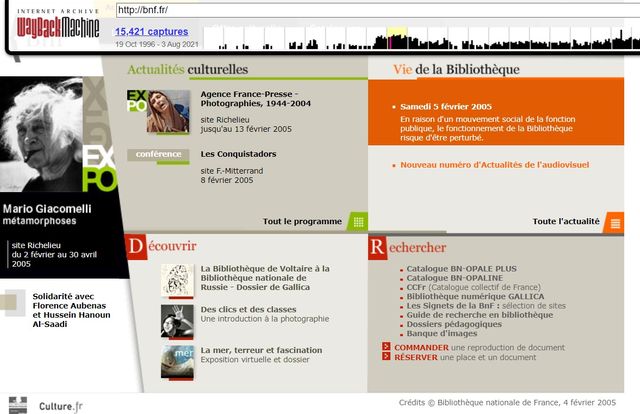
Capture d’écran du site de la BnF le 4 février 2005 / archive.org
Aujourd’hui, après 25 ans d’existence, Archive.org se heurte à deux problèmes. Tous ces documents, reflètent l’état des connaissances conservées par le monde occidental, avec les biais que l’on connait aujourd’hui, notamment la faible part réservée aux femmes. Une mission de rééquilibrage qu’Internet Archive ne s’est pas donnée. Enfin, le principe du grand partage se heurte à la conception du copyright et des droits commerciaux des éditeurs américains. Hachette, HarperCollins, Wiley et Penguin Random House, accusent la plateforme Internet Archive, de nuire à leur business puisqu’elle propose des prêts de livres numériques.
L’organisation à but non lucratif, qui emploie environ 200 personnes, fêtera officiellement ses 25 ans le 21 octobre prochain. Sur son blog, Brewster Kahle explique désormais, « *Pour l’avenir, nous pouvons avoir des écrits non pas de cent millions de personnes, mais d’un milliard de personnes, préservés pour toujours. Nous pouvons avoir des systèmes de rémunération qui ne sont pas guidés par des modèles publicitaires qui n’en enrichissent que quelques-uns. Au cours des 25 dernières années, nous avons accumulé des milliards de pages, 70 pétaoctets de données à offrir à la prochaine génération. Offrons-le-leur de manière nouvelle et excitante. Soyons les bâtisseurs et les rêveurs des vingt-cinq prochaines années ».